
In this article, regular expressions of currency (e.g., US$100, £0.12, or HK$54), time, and date are listed out for quick copy and paste. They’re battle-tested, since our very own form and document data extraction service, FormX, use them frequently in the extraction process. While each regex comes with limitations, we have notes addressing that along with customization tips. There are also code snippets written in Python to let you try customizing and using them.
In the latter parts, we’ll discuss the accuracy of these regexes (i.e., if they can correctly extract information from your target), and provide some possible alternatives. All regular expressions and code snippets here are written in Python.
We developed all the regexes and ways of data extraction here through trial and error, back when we were researching all kinds of receipt scanners and trying to construct a more complete one.
Regex Currency
Copy and Paste Time!
r'$?(?:(?:[1-9][0-9]{0,2})(?:,[0-9]{3})+|[1-9][0-9]*|0)(?:[.,][0-9][0-9]?)?(?![0-9]+)'
Interactive Code Snippet
Note that currency signs apart from “$” will be dropped. The currency value will still gets matched, i.e., pound sterling sign £ in the first item of the test array.
Regex Time
Copy and Paste Time!
r'(?=((?: |^)[0-2]?d[:. ]?[0-5]d(?:[:. ]?[0-5]d)?(?:[ ]?.?m?.?)?(?: |$))'
Interactive Code Snippet
Regex Date with months in English (YYYY/MMMM/dd)
Copy and Paste Time!
'(?=((?:(?:[0][1-9]|[1-2][0-9]|3[0-1]|[1-9])[/-,.]?(?:jan|feb|mar|apr|may|jun|jul|aug|sep|oct|nov|dec)[/-,.]?(?:19|20)?d{2}(?!:)|'
'(?:19|20)?d{2}[/-,.]?(?:jan|feb|mar|apr|may|jun|jul|aug|sep|oct|nov|dec)[/-,.]?(?:[0][1-9]|[1-2][0-9]|3[0-1]|[1-9])|'
'(?:jan|feb|mar|apr|may|jun|jul|aug|sep|oct|nov|dec)[/-,.]?(?:[0][1-9]|[1-2][0-9]|3[0-1]|[1-9])[/-,.]?(?:19|20)d{2}(?!:)|'
'(?:jan|feb|mar|apr|may|jun|jul|aug|sep|oct|nov|dec)[/-,.]?(?:[0][1-9]|[1-2][0-9]|3[0-1]|[1-9])[/-,.]?d{2})))'
Interactive Code Snippet
Get rid of the $ sign if you don’t want the regex to end with a line, i.e., your matching target is a long sentence where the date value is only part of it.
If you are looking for other matching patterns, such as a regex for date MM/DD/YYYY, simply move the capturing groups.
Regex Date of Digits with No Delimiter
Copy and Paste Time!
r'(?:20|19)d{2}(?:0[1-9]|1[0-2])(?:0[1-9]|[1-2]d|3[0-1])'
Interactive Code Snippet
Regex Date of Digits with Delimiters
Copy and Paste Time!
(?=((?:(?:(?:0[1-9]|1[0-2]|[1-9])(?:3[0-1]|0[1-9]|[1-2]d|[1-9])|(?:3[0-1]|0[1-9]|[1-2]d|[1-9])(?:0[1-9]|1[0-2]|[1-9]))(?:19|20)?d{2}(?!:)|(?:19|20)?d{2}(?:0[1-9]|1d|[1-9])(?:3[0-1]|0[1-9]|[1-2]d|[1-9](?!d)))))
Interactive Code Snippet
Play with the part to sub in your delimiters.
Removing Noise from Date
Our end product of date has the format, YYYY/MM/DD. Here’s an example of extracting it:
Bonus: Debit/Credit Card Regex
A huge disclaimer: Never depend your code on card regex. The reason behind is simple. Card issuers carry on adding new card number patterns or removing old ones. You are likely to end up with maintaining/debugging the regular expressions that way.
It’s still fine to use them for visual effects, like for identifying the card type on the screen.
Amex Card: ^3[47][0-9]{13}$
BCGlobal: ^(6541|6556)[0-9]{12}$
Carte Blanche Card: ^389[0-9]{11}$
Diners Club Card: ^3(?:0[0-5]|[68][0-9])[0-9]{11}$
Discover Card: ^65[4-9][0-9]{13}|64[4-9][0-9]{13}|6011[0-9]{12}|(622(?:12[6-9]|1[3-9][0-9]|[2-8][0-9][0-9]|9[01][0-9]|92[0-5])[0-9]{10})$
Insta Payment Card: ^63[7-9][0-9]{13}$
JCB Card: ^(?:2131|1800|35d{3})d{11}$
KoreanLocalCard: ^9[0-9]{15}$
Laser Card: ^(6304|6706|6709|6771)[0-9]{12,15}$
Maestro Card: ^(5018|5020|5038|6304|6759|6761|6763)[0-9]{8,15}$
Mastercard: ^(5[1-5][0-9]{14}|2(22[1-9][0-9]{12}|2[3-9][0-9]{13}|[3-6][0-9]{14}|7[0-1][0-9]{13}|720[0-9]{12}))$
Solo Card: ^(6334|6767)[0-9]{12}|(6334|6767)[0-9]{14}|(6334|6767)[0-9]{15}$
Switch Card: ^(4903|4905|4911|4936|6333|6759)[0-9]{12}|(4903|4905|4911|4936|6333|6759)[0-9]{14}|(4903|4905|4911|4936|6333|6759)[0-9]{15}|564182[0-9]{10}|564182[0-9]{12}|564182[0-9]{13}|633110[0-9]{10}|633110[0-9]{12}|633110[0-9]{13}$
Union Pay Card: ^(62[0-9]{14,17})$
Visa Card: ^4[0-9]{12}(?:[0-9]{3})?$
Visa Master Card: ^(?:4[0-9]{12}(?:[0-9]{3})?|5[1-5][0-9]{14})$
Are regular expressions enough to accurately locate target data?
Here, we’ll use a receipt as an example. Our objective is to obtain {Date}, {Time}, and {Currency} from a receipt image with only regular expressions and an OCR service.
Below, we have a dining receipt and text generated by OCR. We obtained the latter by directly uploading the receipt image to Google Vision API. The response from Google contained a lot more properties, but since we only need the text, we discarded the others.

PizzaExpress Shop 121, level 1, New Town Plaza Phasel, 18 Shat in Centre Street, Slatin TEL: (852) 2670-1238 Order# 1669706 Station POS Eat In Order Seat Count 5 Server: Sze Wan (Shan) W Table: 56 Date: 3/9/2019, 7:24 PM Antipasti Board (1) Partisan Mushroom Dip Chicken Apple (L) Baby Scallop Linguine Panceila Garden A Service charge HK$153.00 HK$63.00 HX0123.00 HK$143.00 } HK$130.00 HK$62.00 Subtotal: Total Tax: HK082.00 ) HK$0.00 Total: HK$662,00 Order Balance due: HK$662.00 Tharik You. Your next meal could be on us! Simply tell us how you feel at pizzaexpress.com.hk/feedback Deliveroo New Customers Offer T&Cs applied
OCR Text from Image with Google Vision API
You might want to try this yourself, so you can head over to Google Vision. Note that the text chunks are scattered throughout the response from Google. A sentence, like “A fox jumps over the lazy dog,” will probably be returned as [“fox”, ” jumps”, ” over”…] along with some other properties. You’ll have to write your own mapping function to assemble them into one piece and filter out unnecessary information.
Obtain { Date, Time, Currency } with Regex
Now we’ll feed the text through a series of regex functions and see what information they can extract.
The result from the above code snippet should look like this:
Time: [' 7:24 '] Date: ['3/9/2019'] Currency: ['121', '1', '18', '852', '2670', '1238', '1669706', '5', '56', '3', '9', '2019', '7', '24', '1', '$153.00', '$63.00', '123.00', '$143.00', '$130.00', '$62.00', '82.00', '$0.00', '$662,00', '$662.00']
The date and time regexes were enough to pull their target out from the receipt. For the currency, it somewhat achieved its task by yielding a list of possible currency values.
If you’re looking for all matches instead of the most likely one for each target, the regexes are what you need. A possible use case would be implementing regex date validation in your front-end screens.
If not, i.e., you only want some specific ones, you’ll need something more powerful. The first two fulfilled their purpose only because our receipt image contained a single and valid time and date candidate. If there were more than one, they would end up with results like the one we got from the currency regex. We’ll get to this in the next section.
Also, the example we have here is a bit limited. Let’s consider a more extensive objective. What if we are to extract {date}, {time}, and {currency from various types of receipts?
The format of each target can vary among the receipts. A possible solution is to adopt a wider range of regexes. Rather than just one, we can adopt more than 10 regexes to obtain time.
It’s also worth noting that if the extraction results will be passed on to other services, an interface to normalize their data structure should be added to ensure consistency. Take the date result as an example. You’d probably want to transform each one of them to follow the ISO 8601 format, YYYY-MM-DD. In this case, the result from the above, ‘3/9/2019’, will become ‘2019-09-03’.
Obtain Target Data with AI models
Another important tip: Never ever depend on regex when you’re only expecting one correct result (i.e., the total amount from a receipt). Our team actually encountered all the issues we noted earlier.
To address these issues, we decided to apply a layer of AI models on the top of OCR services and regexes. This ensures that only the most likely one is extracted for each type of target data. It’s like adding a function to further filter out the results from regex searches.
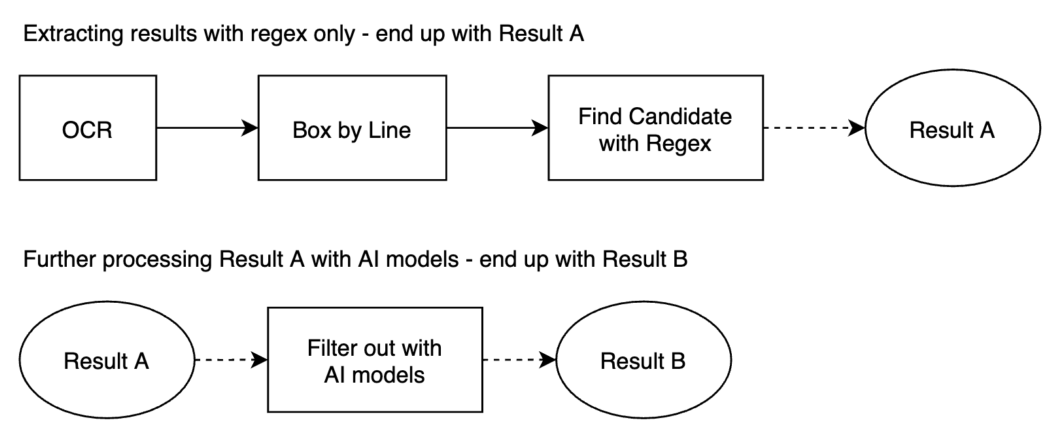
In the diagram above, most processes have been elaborated. Here, we’ll quickly look into the uncovered ‘Box by Line’.
Like we mentioned, every chunk of text in the OCR response from Google Vision API comes with some other properties. One of them is a bounding box indicating the location of a text chunk, which is formed by the x and y coordinates of the text’s four corners.
Based on these locations, the ‘Box by Line’ process groups the text chunks (from the OCR) with relatively horizontal lines to capture location-related features. A {date} is most likely to pop up in top or bottom parts of a receipt, with a {time }candidate in the same or adjacent lines. If you want to know more about how we extracted receipt data, I wrote another article focusing just on that.
In short, result B is simply a subset of result A, filtered by some AI models.
In the flow above, we can extract a lot more than just {date}, {time}, and {currency} from all kinds of text pieces.
Now let’s see how our solution, FormX, can obtain the targets from the sample receipt image. You’ll see that the outputs from FormX are normalized and consistent, with all unnecessary noises trimmed to facilitate future development.
In fact, FormX can extract data from not only receipts but all kinds of documents. To test the features, simply sign up to get 100 of free API calls!

Summing Up Regex
The list of regexes in this article should get your through a lot of data validation or data extraction tasks. However, to boost extraction precision, you may need something more powerful, like machine learning models.
What’s your approach to solve a data extraction problem? What do you use when you only need some specific ones instead of all? Feel free to comment below to let us know!






