
We wrote this after the Oursky Skylab.ai team completed an AI content generator for a startup client, and we’d like to share our experience and journey. From a corpus of stories with an aligned writing style, provided by our client, we trained a text generation model that outputs similar text pieces.
In this technical report, we will:
- Go through what a language model is.
- Discuss how to use language modeling to generate articles.
- Explain what Generative Pre-Trained Transformer 2 (GPT-2) is and how it can be used for language modeling.
- Visualize text predictions – print out our GPT-2 model’s internal states where input words affect the next’s prediction the most.
Demo with a Generic GPT-2
Let’s start with a GIF showing the outputs from a standard GPT2 model, when it was fed with 1. a sentence randomly extracted from a Sherlock Holmes book, 2. the definition of Software Engineering on Wikipedia.
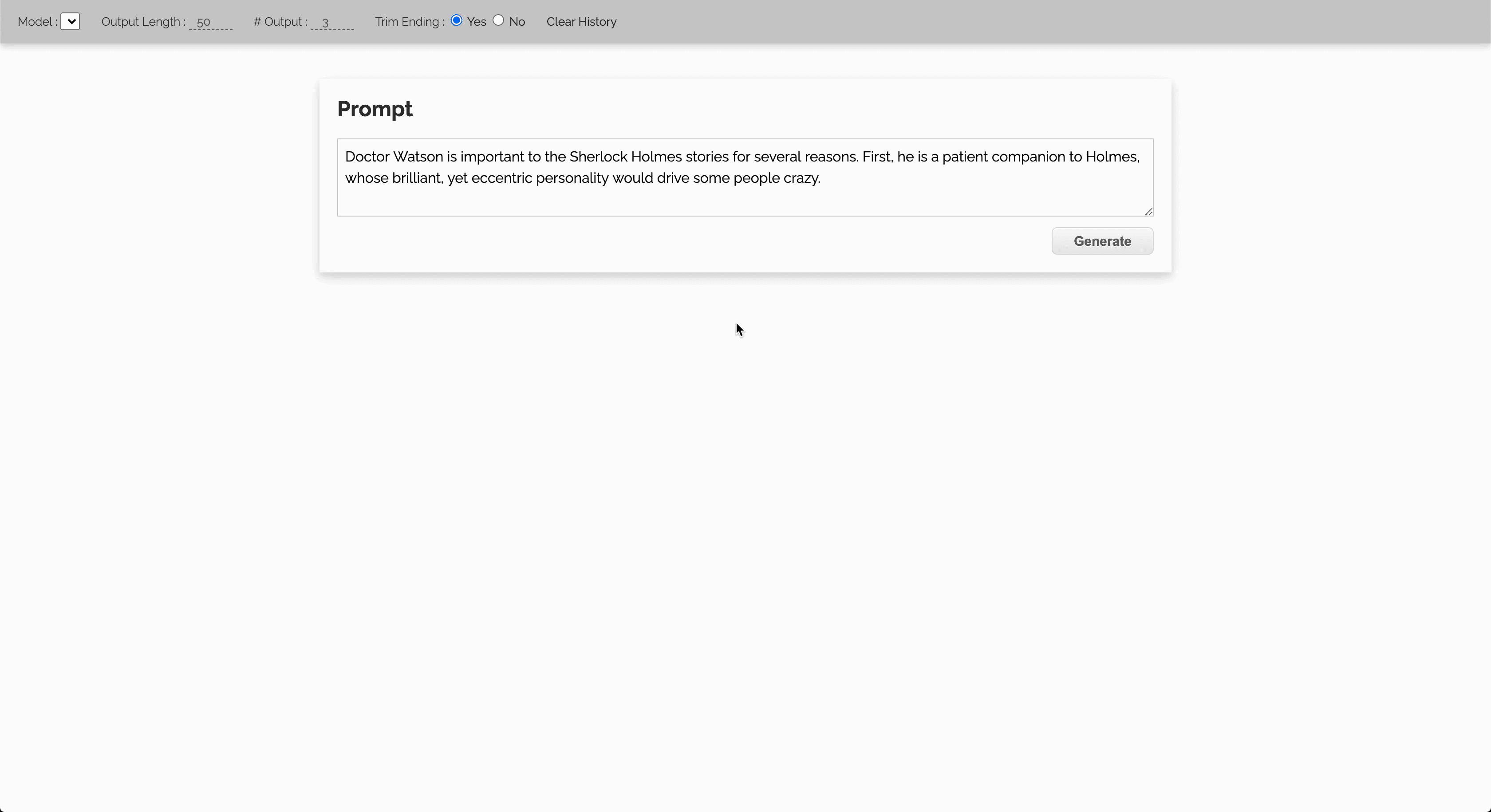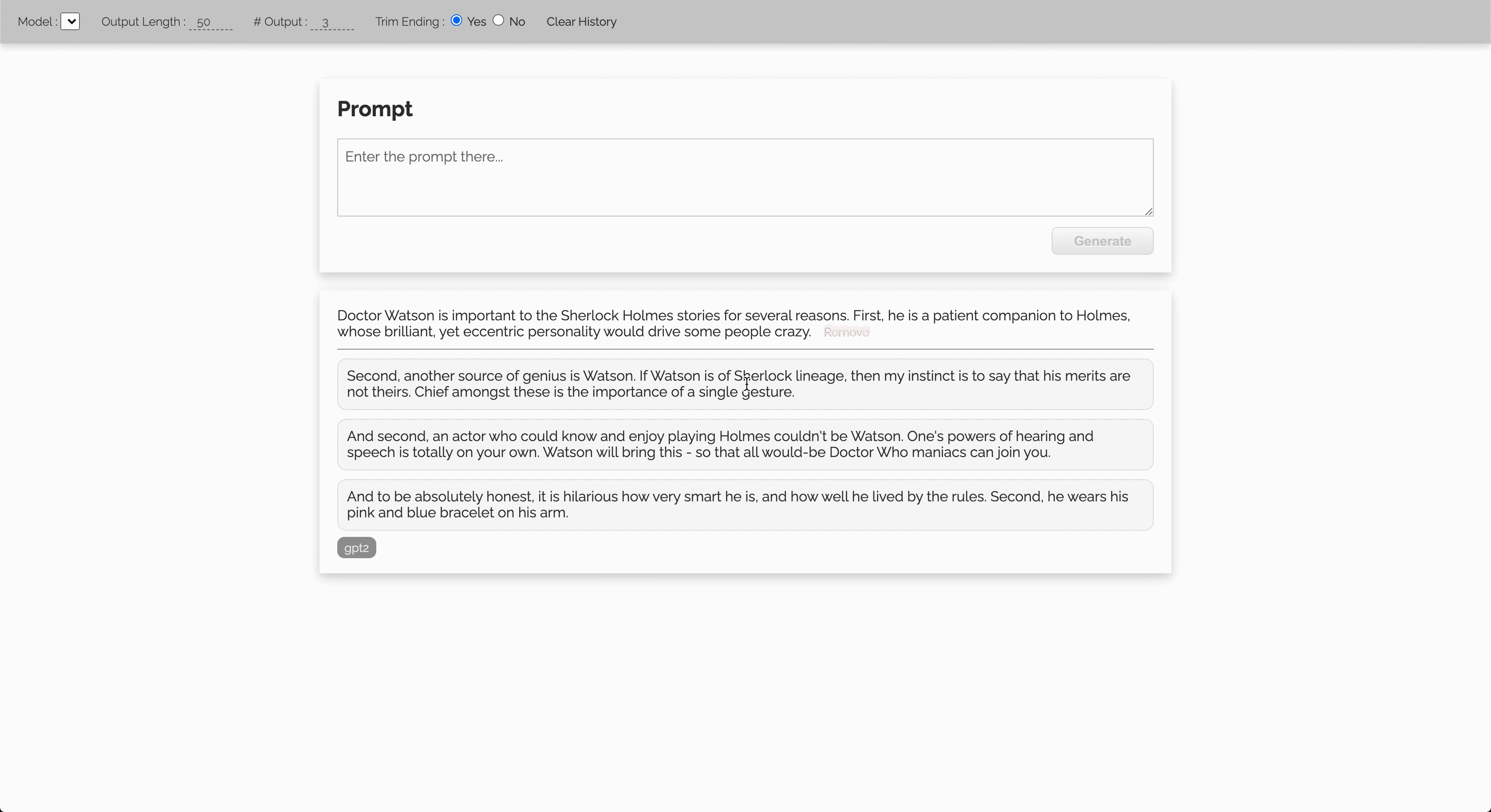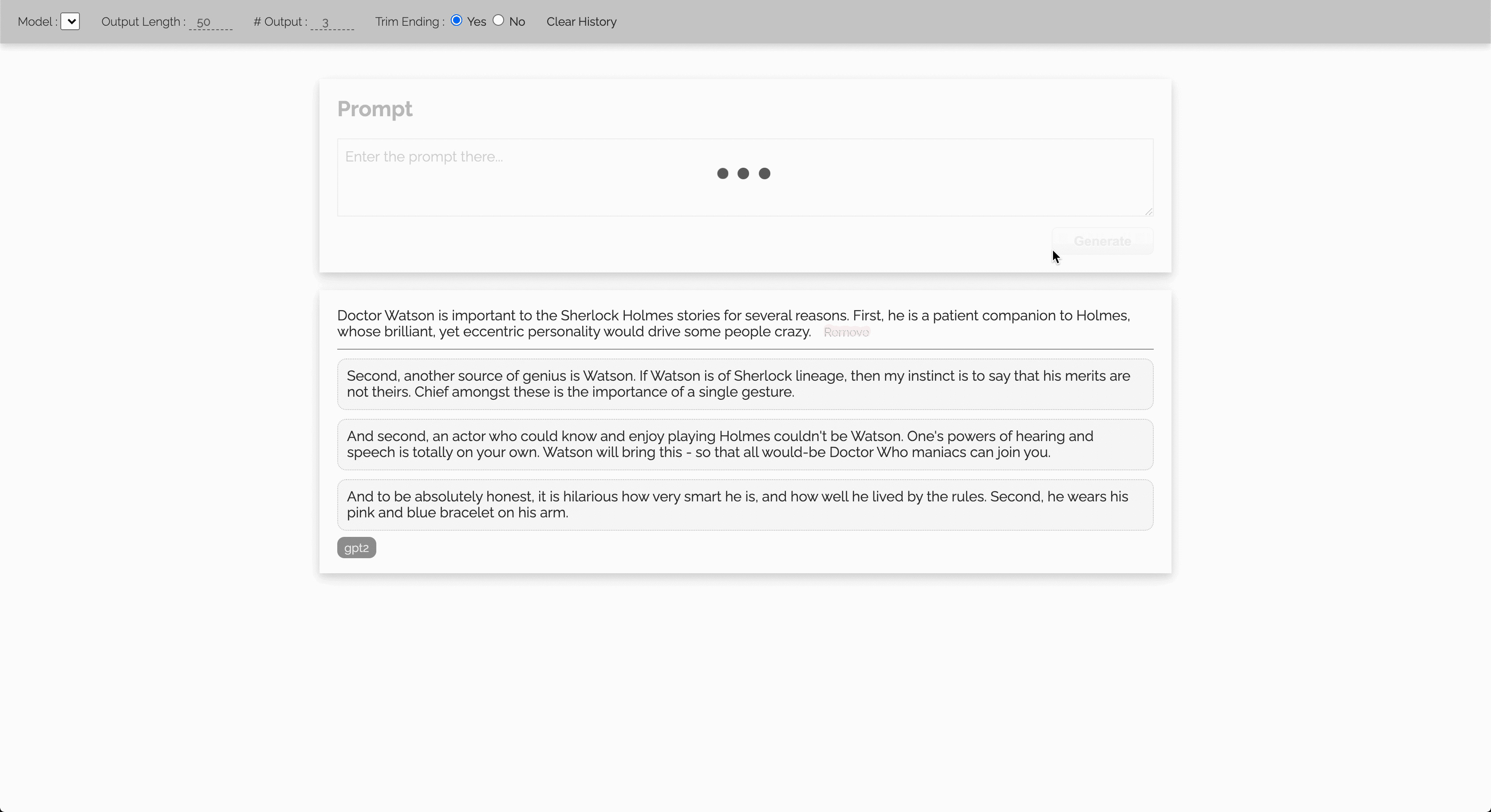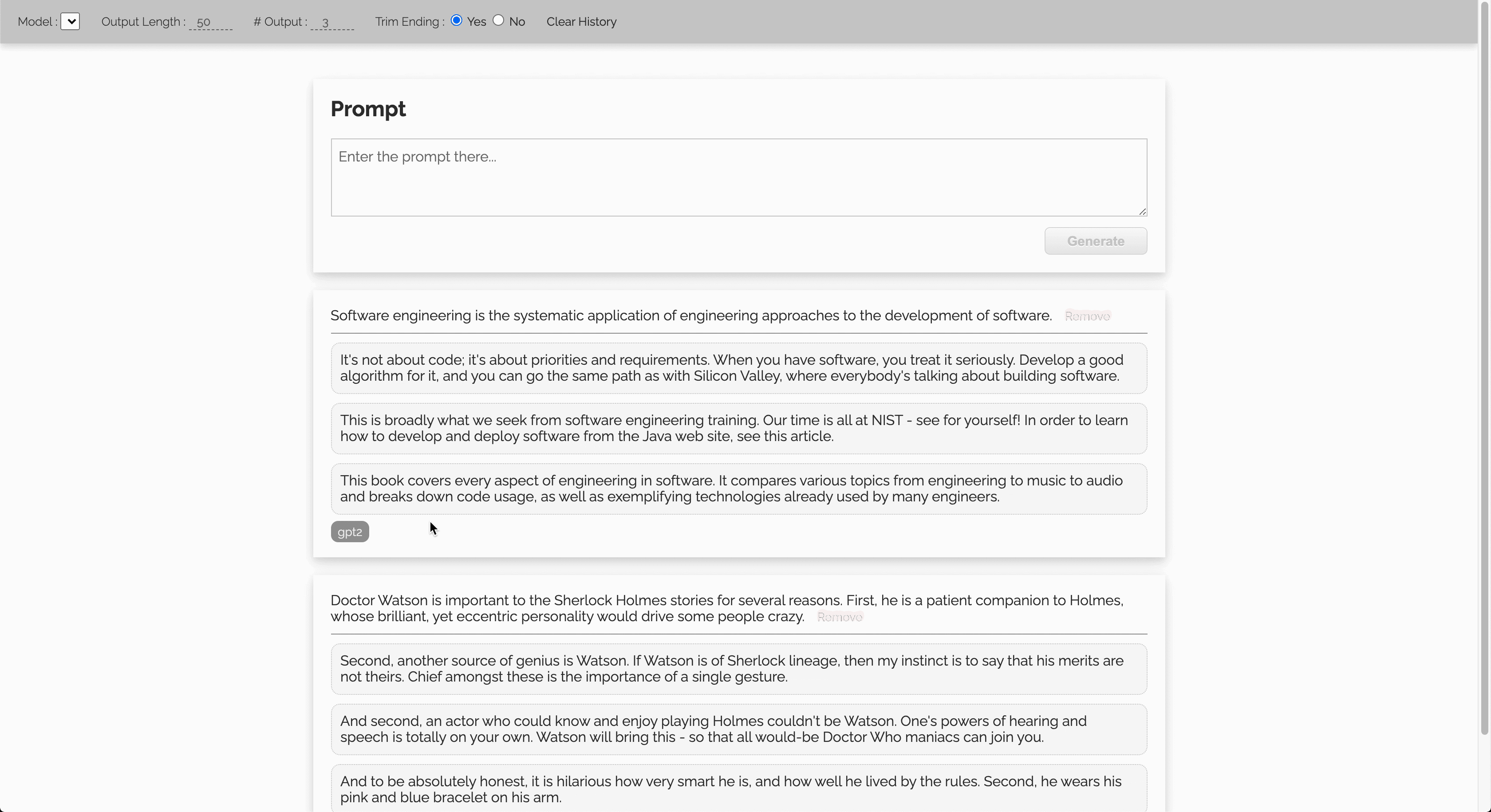
Prerequisites
- Basic knowledge on Natural Language Processing with python
- Understandings on Probability Theory
Before we start building a predictive text generator, let’s go through a few concepts first.
Language Model
A language model is just a probability distribution of a sequence of words. For example, given a language model of English, we can ask the probability of seeing a sentence, “All roads lead to Rome,” in English.
We could also estimate that the probability of seeing grammatically wrong or nonsensical sentences – “jump hamburger I” definitely has a much lower probability of being correct than “I eat hamburger”.
Let’s pull in some mathematical notations to describe a language model better.
P(w1, w2, …, wn) means the probability of having the sentence “w1 w2 … wn”. Here, the language model is a probability distribution instead of a probability. Having a probability distribution means we can tell the value of P(All, roads, lead, to, Rome) or P(I, eat, hamburger) if we know any wi=1…n for any n in P(w1, w2, …, wn).
A bit on the notation first. Whenever you see P(hello, world), where items inside P() are actual words, P() is then describing a probability since wi=1…n and n are known (the former = “hello”, “world” while the latter = 2). If items inside P() are unknown, P() is then indicating a probability distribution. From here on out, we’ll use “probability” and “probability distribution” interchangeably used unless specified.
Sometimes, it’s more convenient if we express P(w1, w2, …, wn) as P(w, context). What happens here is that we lump w1 to wn-1 (i.e., all words of a sentence except the last one) to a bulky stuff that we call “context.” We can then calculate the chance of being in this “context” (seeing previous n-1 words) and ending up with the word “w” at the end.
Here, P(w1, w2, …, wn) and P(w, context) are describing the same thing.
Using chain rule, we could write P(w, context) as P(w | context) P(context). We’d like to do this because P(w | context) is, in fact, the target we want most of the time. P(w | context) here is a conditional probability distribution. It tells the chance of seeing a word w given that the context (i.e. previous words) is known.
Now let’s put in some words to P(w | context), say, P(apple | context) or P(orange | context). Assuming we have the previous words, we can start predicting how likely it is to have “apple” or “orange” as the next word of this sentence. By obtaining the “mostly likely next word,” we can start creating some article generation AI models.
Right, so now we need a language model. How do we get one? Another article answers this question.
One approach is to count the number of wn that comes after w1 to wn-1 on a large text corpus, which will build a n-gram language model. Another is to directly learn the language model using a neural network by feeding lots of text.
In our case, we used the latter approach by using the GPT-2 model to learn the language model.
Text Generation with a Language Model
As mentioned, P(w | context) is the basis for a neural network text generator.
P(w | context) tells the probability distribution of all English words given all seen words (as context). For example, for P(w | “I eat”), we would expect a higher probability when w is a noun rather than a verb. The likelihood of w being a food is much higher than other nouns like “book”.
To generate the next word with all seen words, we could keep adding one word at a time with P(w | context) until we have enough for a sentence or have reached some “ending word” like a full stop.
There are various approaches on how to pick the next word, which we discuss below.
Greedy Approach
One approach is to pick the word with the highest probability. A quick example would be:
P(w | “I eat”), where “hamburger” has the highest probability of being w among all words from a dictionary. We call this the greedy approach for sentence generation.
This approach is quick and very simple. The main drawback is that for the same set of previous words, we will always generate the same sentence. In other words, it lacks creativity.
Plus, when we always pick the highest probability, so it’s very easy to fall in the case of degenerate repetition, like getting the same chunk of text during sentence generation. For example:
I eat hamburger for breakfast. I eat hamburger for breakfast. I eat hamburger for breakfast ...
Not so human-like, right? We need something more random to create a language generator that yields human readable sentences.
Beam Approach
Another approach is to generate lots of sentences first, then pick the most likely sentence.
Let’s assume that there are 20,000 words in the dictionary, and we want to generate a sentence with 5 words starting with word “I”. The number of all possible sentences that we could generate will be 200004, or one hundred and sixty quadrillion. Clearly, that’s too many! We cannot calculate all those sentences’ probability within a reasonable time, even with a powerful computer.
Instead of constructing all possible sentences, we could instead just track the top-N partial sentences. At the end, we only need to check the probability of N sentences. By doing so, we hope to search the top-N likeliest sentence without having to try all combinations. This kind of searching is called beam search, and N is the beam width.
The decision tree figure below illustrates a case of generating a sentence with three words, starting with “I” with N = 2. This means we only track top-2 partial sentences.
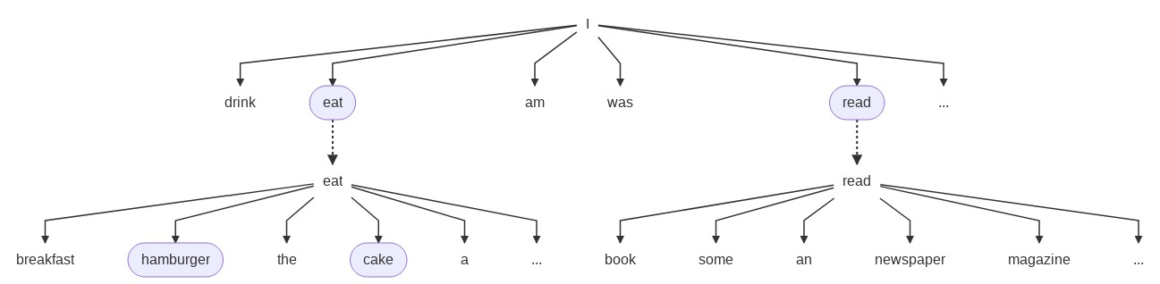
Here, we first check P(w | “I”). Among all the possible words, the language model tells “eat” and “read” are the most probable next words. Hence, in the next step, we’ll only consider the trees of P(w | “I eat”) and P(w | “I read”) and ignore other possibilities like sentences that start with “I drink”.
Afterwards, we repeat the same procedure and find the two most probable words after “I eat” or “I read”. Among all that start with “I eat” and “I read”, P(“hamburger” | “I eat”) and P(“cake” | “I eat”) have the highest two probabilities. We’ll thus only expand the search with sentence prefixes “I eat hamburger” and “I eat cake” while the “I read” branch dies.
We will keep repeating the “expand and pick best-N” procedure until we have a sentence with desired length. This’ll finally return a sentence with the highest probability.
You may already notice that when the beam width is reduced to 1, the beam search will become the greedy approach. When the beam width equals the size of the dictionary, beam search becomes an exhaustive search. Beam search allows us to choose between sentence quality and speed.
With beam width larger than 1, beam search tends to generate more promising sentences. However, like the greedy approach, the lack of randomness remains. The same sentence prefix will lead to the same sentence, and degenerate repetition will likely to happen.
Pure Sampling
The drawbacks of beam search and greedy approaches are due to the fact that we’re picking the most probable choice. Instead of picking the most probable word from P(w | context), we could sample a word with P(w | context). Time to add some randomness!
For example, with a sentence that start with “I”, we can sample a word according to P(w | “I”), as the sampling is random. Even if P(“eat” | “I”) > P(“read” | “I”), we could still sample the word “read”. Using sampling, we’ll have a very high chance of getting a new sentence in each generation.
Sentence generated from pure sampling will be free from degenerate repetition, but it tends to result in some gibberish.
Top-k Sampling and Sampling with Temperature
There are common ways to improve pure sampling.
There’s Top-k sampling. Instead of sampling from full P(w | context), we only sample from top K words according to P(w | context).
Another is sampling with temperature. It means we reshape the P(w | context) with a temperature factor t, where t is between 0 and 1.
This is where we’re using a neural network to estimate a language model. Instead of probability values (which are in the range of 0 to 1), we are getting a real number that could be in any range, which is called logits. We can convert logits to probability value using the softmax function.
Temperature t is a part in applying the softmax function to retrieve the probabilities. This is to reshape the resultant P(w | context) by dividing each logit value by t before applying the softmax function. As t is between 0 and 1, dividing it will amplify the logit value.
Summing up, more probable words become even more probable while the less probable ones become even less probable. Top-k sampling and sampling with temperature usually are applied together.
Nucleus Sampling
When using Top-k sampling, we need to decide which k to use. The best k varies depending on context. The idea of Top-k sampling is to ignore very unlikely words according to P(w | context).
We can do this in another way. Instead of focusing on Top-k words in sampling, we filter out words whose sum of probabilities is less than a certain threshold, and we only sample from the remaining words.
This approach is called nucleus sampling. According to The Curious Case of Neural Text Degeneration, the original paper that proposed nucleus sampling, we should choose p = 0.95, which implies that the threshold value is 1-p = 0.05. By doing nucleus sampling with p = 0.95, we could generate text pieces that are statistically most similar to human-written text.
The paper is a must-read! It provides a lot of comparison among human-written text and texts generated through various approaches (beam search, top-k sampling, nucleus sampling, etc.), measured by different metrics.
Introduction to GPT-2 Model
Time to dive into the AI model!
Like we mentioned, we used a neural network, GPT-2 model from OpenAI, to estimate the language model.
GPT-2 is a Transformer-based model trained for language modelling. It can be fine-tuned to solve a diverse amount of natural language processing (NLP) problems such as text generation, summarization, question answering, translation, and sentiment analysis, among others.
Throughout this article some NLP Python code snippets will be provided to aid reading.
Diving into the GPT-2 model itself deserves a separate blog. Here, we’ll focus on a few main concepts. We highly recommend reading two awesome articles from Jay Alammar on Transformer and GPT-2 for more in-depth information.
Here, we’ll talk about how GPT-2 model works by building it piece by piece.
Example of GPT 2 – Input and Output
First, let’s describe the input and output of the GPT-2 model. We’ll start small and seek to construct a sentence first.
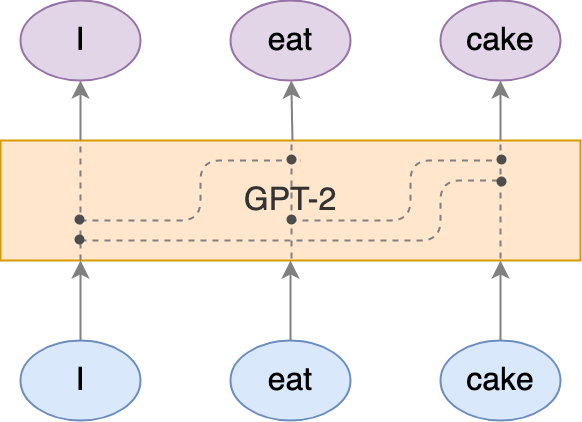
Given words in its embedded form, GPT-2 transforms the input word-embedding vector (blue ellipses) to the output word embedding (purple ellipses). This transformation would not change the dimension of the word embedding (although it could). Output word embedding is known as the hidden state.
During the transformation, input embeddings from previous words will affect the result of the current word’s output embedding, but not the other way round. In our example, the output embedding of “cake” will depend on the input embedding of “I”, “eat”, and “cake”. On the other hand, the output embedding of “I” (the first word) will only depend on the input embedding of “I”.
Due to this, the output embedding of the last input word somehow captures the essence of the whole input sentence.
To obtain the language model, we could have a matrix WLM whose number of column equals the dimension of output embedding. WLM has a number of rows that equals the dictionary size and bias vector bLM with its dimension being the dictionary size.
We can then compute the logit of each word in the dictionary by multiplying WLM with the output embedding of the last word, then adding bLM. To convert those logits to probabilities, we’ll apply the softmax function, and its result could be interpreted as P(w | context).
Inside the GPT-2 Model
Until now, we’ve discussed how output word embeddings are computed from input word embeddings.
Input word embeddings are simply vectors. The first steps of the transformation is to create even more vectors from those input word embeddings. Three vectors, namely, the key vector, query vector and value vector, will be created based on each input word embedding.
Producing these vectors is simple. We just need three matrices Wkey, Wquery, and Wvalue. By multiplying the input word embedding with these three matrices, we’ll get the corresponding key, query, and value vector of the corresponding input word. Wkey, Wquery and Wvalue are parts of the parameters of the GPT-2 model.
To further demonstrate, let’s consider Iinput , the input word embedding of “I”. Here, we have:
Ikey = Wkey Iinput, Iquery = Wquery Iinput, Ivalue = Wvalue Iinput
We’ll use the same Wkey, Wquery and Wvalue to compute the key, query, and value vectors for all other words.
After we know how to compute the key, query, and value vectors for each input word, it’s time to use these vectors to compute the output word embedding.
As mentioned, the current word’s output embedding will depend on the current word’s input embedding and all the previous words’ input embedding.
The output embedding of a current word is the weighted sum of the current word and all its previous words’ value vectors. This also explains why value vectors are called as such.
Let’s take eatoutput as the output embedding of “eat”. Its value is computed by:
eat output = I A eat I value + eat A eat eat value
Here, I A eat and eat A eat are attention values. They could be interpreted as how much attention should “eat” pay on “I” and “eat” when computing its output embedding. To avoid shrinking the output embedding, the sum of attention values need to be to 1.
This implies that for the first word, its output embedding will be equal to its value vector; for example, Ioutput equals to I value.
Each attention value xAy is computed by:
- Taking the dot product between the key vector of x and query vector of y
- Scaling down the dot product with the square root of the dimension of the key vector
- Taking the softmax to ensure the related attention values are summing up to 1, as shown below:
xAy = softmax(xkeyT yquery / sqrt(k)), where k is the dimension of key vector.
Let’s recap!
We should now know how output embedding is computed as the weighted sum of value vectors of the current and previous words. The weights used in the sum are called attention value, which is a value between two words, and is computed by taking the dot product of key vector of one word and query vector of another word. As the weights should sum up to 1, we’ll also take the softmax on the dot product.
Structure Replication
What we’ve discussed so far is just the attention layer in GPT-2. This layer covers most of the details, as the rest of the GPT-2 model structure is just a replication of the attention layer.
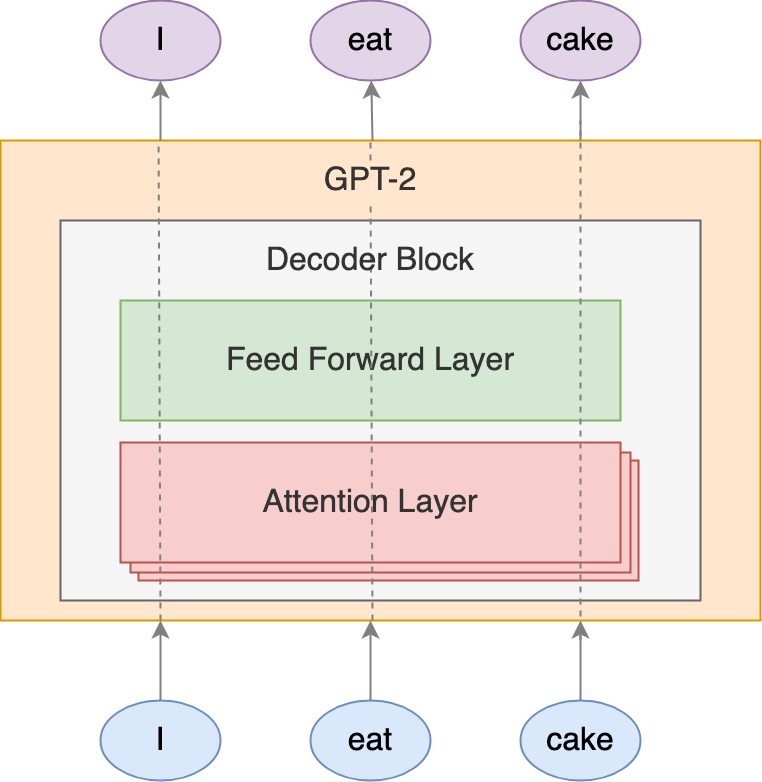
Let’s continue our GPT-2 model construction journey. GPT-2 uses multiple attention layers. This is the so-called multi-head attention.
While those attention layers run in parallel, they’re not dependent on each other and don’t share weights, i.e., there will be a different set of Wkey, Wquery, and Wvalue for each attention layer.
As we have multiple attention layers, we’ll have multiple output word embeddings for each word. To combine all those output word embeddings into one, we’ll first concatenate all the output word embeddings from different attention layers. We then multiply the concatenated matrix Wproject to make the output word embedding have the same dimension as the input word embedding.
The output word embeddings we got so far is actually not the final one. The output word embeddings will further go through a feedforward layer and transform into actual output word embeddings.
These attention layers running in parallel together with the feedforward layer are grouped to a block called the decoder block1.

GPT-2 doesn’t just include one decoder block. There’s a chain of it. We choose the input word embedding and output word embedding to have the same dimensionality so that we could chain the decoder blocks.
These decoder blocks have exactly the same structure but don’t share weight.
The GPT-2 model has a different sizes. They are different in the embedding dimensionality, key, query, value vector’s dimensionality, number of attention layer in each decoder block, and number of decoder blocks in the model.
Some Omitted Details
Here are some details worth noting, and you can take these as pointers to learn more about them:
- GPT-2 uses Byte pair encoding when tokenizing the input string. One token does not necessarily correspond to one word. GPT-2 works in terms of tokens instead of words.
- Positional embeddings are added to the input embeddings of the first decoder block so as to encode the word order information in the word embedding.
- All residual addition and normalization layers are omitted.
Training the GPT-2 Model
So, now you have a sense of how GPT-2 works. You know how GPT-2 can be used to estimate the language model by converting last word’s output embedding to logits using WLM and bLM, then to probabilities.
We can now talk about training the GPT-2 model for text generation.
The first step to train a GPT-2 text generator is language model estimation. Given an input string, such as “I eat cake”, GPT-2 can estimate P(eat | “I”) and P(cake | “I eat”).
For this input string in training, we’ll assume the following:
P(eat | “I”) = 1, P(w != eat | “I”) = 0
P(cake | “I eat”) = 1, P(w != cake | “I eat”) = 0
Now that we have estimated and targeted the probability distributions, we can then compute the cross entropy loss, and use this to update the weights.
As you’ll see, we need to feed it with a large amount of text to train the GPT-2 model.
Testing and Fine-Tuning GPT-2
To quickly test GPT-2 on article generation, we’ll use Huggingface🤗 Transformers. It is a Python library for developers to quickly test pre-trained and transformers-based NLP models. GPT-2 is one of them, along with others like PyTorch and TensorFlow.
To fine-tune a pre-trained model, we could use the run_langauge_modeling.py. All we need are two text files; one containing the training text pieces, and another containing the text pieces for evaluation.
Here’s an example of using run_language_modeling.py for fine-tuning a pre-trained model:
python run_language_modeling.py \
--output_dir=output \ # The trained model will be store at ./output
--model_type=gpt2 \ # Tell huggingface transformers we want to train gpt-2
--model_name_or_path=gpt2 \ # This will use the pre-trained gpt2 samll model
--do_train \
--train_data_file=$TRAIN_FILE \
--do_eval \
--eval_data_file=$TEST_FILE \
--per_gpu_train_batch_size=1 # For GPU training only, you may increase it if your GPU has more memory to hold more training data.
Huggingface🤗 Transformers has a lot of built-in functions, and generating text is one of them.
The following is a code snippet of text generation using a pre-trained GPT-2 model:
from transformers import (
GPT2LMHeadModel,
GPT2Tokenizer,
)
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
model = GPT2LMHeadModel.from_pretrained("gpt2")
sentence_prefix = "I eat"
input_ids = tokenizer.encode(
sentence_prefix,
add_special_tokens=False,
return_tensors="pt",
add_space_before_punct_symbol=True
)
output_ids = model.generate(
input_ids=input_ids,
do_sample=True,
max_length=20, # desired output sentence length
pad_token_id=model.config.eos_token_id,
)[0].tolist()
generated_text = tokenizer.decode(
output_ids,
clean_up_tokenization_spaces=True)
print(generated_text)
Attention Visualization
Thanks to jessevig’s BertViz tool, we can peek at how GPT-2 works by visualizing the attention values.

The figure above is a visualization of attention values on each decoder block (from top to bottom of the grid, with the first row as the first block). Each attention head (from left to right) of the GPT-2 small model takes “I disapprove of what you say, but” as input.
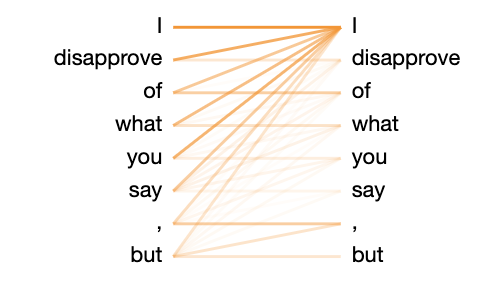
On the left is a zoomed-in look at the 2nd block’s 6th attention head’s result.
The words on the left are the output, and those on the right are the input. The opacity of the line indicates how much attention the output word paid to the input words.
An interesting tidbit here is that, most of the time, the first word is paid the most attention. This general pattern remains even if we use other input sentences.
Word Importance Visualization
Purely looking at the attention values doesn’t seem to give us clues on how the input sentence affects how the GPT-2 model picks its next word. One of the reasons could be that it’s hard to imagine how the attention is utilized for the next word text prediction, as there’s still a Wproject feedforward layer to transform the attention layer’s output.
So, we’re interested in how the input sentence affects the probability distribution of the next word. We want to know which word in the input sentence will affect the next word’s probability distribution the most.
Measure Word Importance Through Input Perturbation
In Towards a Deep and Unified Understanding of Deep Neural Models in NLP, the authors propose a way to answer this. They also provide the code that we could use to analyze the GPT-2 model with.
The paper also discussed measuring the importance of input word. The idea is to assign a value σi to each input word, where σi is initially a random value between 0 and 1.
Later on, we’ll generate some noise vector with the size of input word embedding. This noise vector will be added to the input word embedding with the weight specified in σi. This means σi tells how much noise is added to the corresponding input word.
With the original and perturbed input word embeddings, we feed both of them to our GPT-2 model and get two sets of logit from the last output embeddings.
We then measure the difference (using L2 norm) between these two logits. This difference tells us how severely the perturbation is affecting the resultant logits that we use to construct the language model. We then optimize σi to minimize the difference between two logits.
We keep generating new noise vector and add them to the original input word embedding using the updated σi. We then compute the difference between the resultant logits, and use this difference to guide the update of σi.
During the iteration, we’ll track the best σi that leads to the smallest difference in the resultant logits, and report it as the result after we reach the maximum number of iteration.
The reported σi tells us how much noise the corresponding input word could withstand in a way that will not lead to significant change in the resultant logits.
If a word is important to the resultant logits, we’d expect that the small perturbation on that word’s input embedding will lead to a significant change in the logits. Hence, the reported σi is inversely proportional to the importance of the words. The smaller the the reported σi, the more important the corresponding input word is.
Code Snippet
Here’s a code snippet for visualizing the word importance. Interpreter.py could be found here.
import torch
from transformers import GPT2Tokenizer, GPT2LMHeadModel
from Interpreter import Interpreter
def Phi(x):
global model
result = model(inputs_embeds=x)[0]
return result[-1,:] # return the logit of last word
model_path = "gpt2"
model = GPT2LMHeadModel.from_pretrained(model_path, output_attentions=True)
tokenizer = GPT2Tokenizer.from_pretrained(model_path)
input_embedding_weight_std = (
model.get_input_embeddings().weight.view(1,-1)
.std().item()
)
text = "I disapprove of what you say , but"
inputs = tokenizer.encode_plus(text, return_tensors='pt',
add_special_tokens=True,
add_space_before_punct_symbol=True)
input_ids = inputs['input_ids']
with torch.no_grad():
x = model.get_input_embeddings()(input_ids).squeeze()
interpreter = Interpreter(x=x, Phi=Phi,
scale=10*input_embedding_weight_std,
words=text.split(' ')).to(model.device)
# This will take sometime.
interpreter.optimize(iteration=1000, lr=0.01, show_progress=True)
interpreter.get_sigma()
interpreter.visualize()
Below are the reported σi and its visualization. The smaller the value, the darker the color.
array([0.8752377, 1.2462736, 1.3040292, 0.55643 , 1.3775877, 1.2515365,
1.2249271, 0.311358 ], dtype=float32)

From the figures above, we can now know that P( w | “I disapprove of what you say, but”) will be affected by the word “but” the most, followed by “what”, then “I”.
Conclusion
To sump up, we discussed what a language model is and how to utilize it to do article generation that uses different approaches to get text similar to how humans write them.
We also briefly introduced the GPT-2 model and some of its internal workings. We also saw how to use Huggingface🤗 Transformers in applying the GPT-2 model in text predictions.
We’ve visualized the attention values in GPT-2 model and used the input perturbation approach to see which word/s in the input sentence would affect the next word prediction the most.
Footnote:
- The actual structure of decoder block consists of one attention layer only. What we describe here as attention layer should be called attention head. One attention layer includes multiple attention heads and the Wproject for combining the attention heads’ output.
Subscribe to Oursky Code Blog for more expert advice for developers – by developers:







2 comments